
How DoorDash Improved Redis to Handle 10+ Million Reads per Second
A handful of insanely clever things DoorDash did to make Redis blazingly fast

DoorDash is an online food delivery service. It allows users to order food from local restaurants and delivers it to their doorstep.
Founded in 2013 by four US students. It has grown to over 19 thousand employees worldwide, with 550,000 restaurants in 2023, and made over 8 billion dollars in revenue that same year.
That’s a lot of growth in 10 years. But there’s more.
In 2022, DoorDash acquired Wolt Enterprises, taking the total number of countries it operates in from 6 to more than 30.
With so many restaurants, giving users an excellent search and recommendation experience is important.
So to do this, the team at DoorDash built a machine learning model that used Redis to store data.
But Redis wasn't coping well with the amount of reads to the data.
So here's how they improved it.
Estimated reading time: 4 minutes 51 seconds
Why Does DoorDash Use ML?
Not all online services use machine learning for their search and recommendations. So why does DoorDash?
The team used traditional methods in the past to suggest restaurants based on a user's location and preferences. Most likely using a search pipeline with Elasticsearch.
But this didn't have the level of personalization users have come to expect. The search and recommendations didn't update dynamically based on user behavior.
So, the team at DoorDash built a machine learning model to learn from its users and make better predictions.
But to do that, they would need to store a lot of data somewhere for fast and easy access. And that somewhere for DoorDash was Redis.
Sidenote: Redis
Redis (Remote dictionary server) is an in-memory data store. In-memory means data is read and modified from computer memory (RAM), not the disk. This makes it incredibly fast.
Redis reads 12x faster than MongoDB and 500x faster than Elasticsearch.
It stores data as key-value pairs where keys are always strings, and values can be any data type.
But, because Redis stores data in memory, all the data must be stored in RAM, which can get expensive for a lot of data. This also means if the server crashes, data not yet written to disk is lost.
Because of that, Redis is commonly used as a cache for data to be retrieved quickly. But, is often paired with other databases for long-term storage.

The team tried using different databases: Cassandra, CockroachDB and Scylla. But they settled on Redis for its performance and cost.
An ML model capable of the predictions DoorDash wanted would need to make tens of millions of reads per second.
As performant as Redis is, it wasn't able to handle that many reads out of the box.
So they needed to massively improve it.
Sidenote: ML Predictions
Why does a machine learning model need to make tens of millions of reads per second?
A machine learning model is essentially a program that finds patterns in data and uses them to make predictions.
So if someone types 'best-running shoes' into a model for recommendations. The model would search for data, like shoe ratings, user's purchase history, shoe specifications, etc.
These pieces of data are called features. This is the input data the model needs to analyze. Features start out as raw data, like shoe data from an application database.
It's then cleaned up and transformed into a format that the model can be trained on and used to make predictions.
This includes creating categories or buckets for data, combining buckets to make new data, and removing redundant data. Things that can help the model find patterns.
All this data is stored in a feature store.
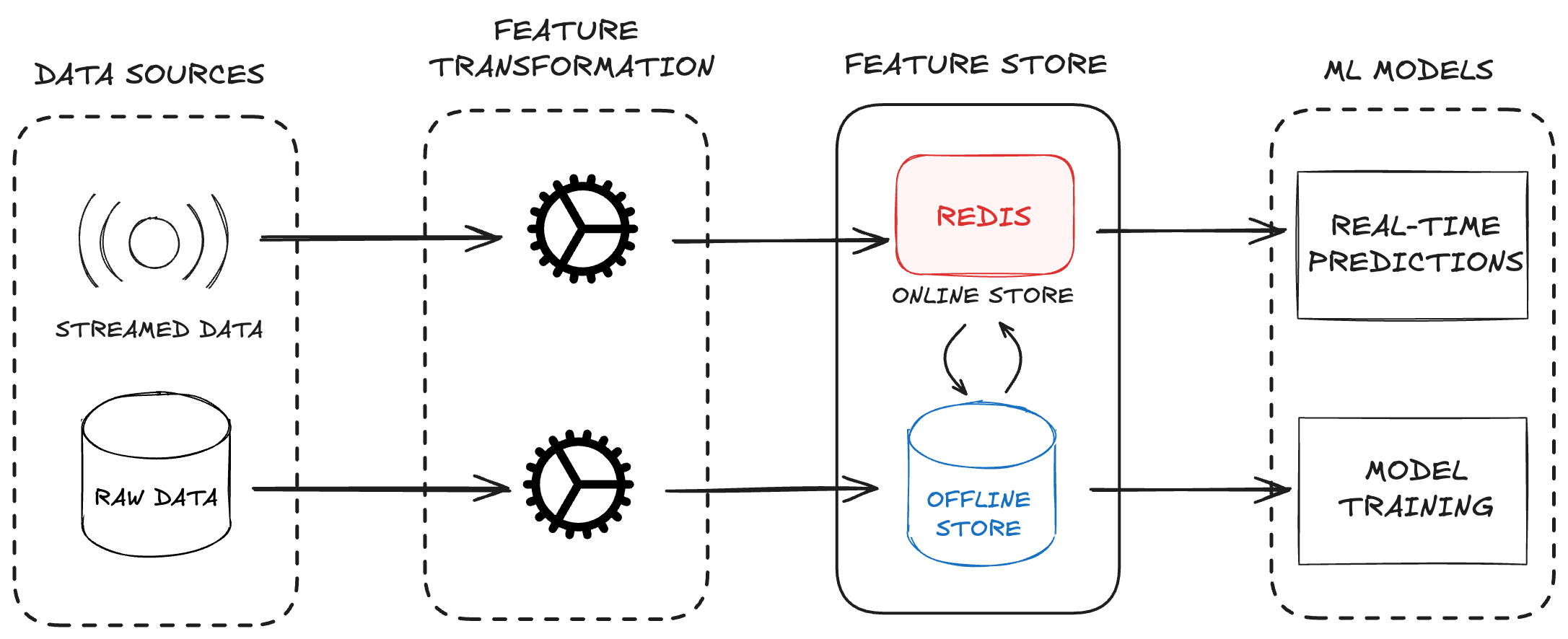
A feature store itself contains two main components: offline and online stores.
Offline stores contains historical data used to train the model. Usually stored on disk-based databases.
Online stores contain the most current data from real-time events used for real-time predictions. This data is often streamed via CDC and stored in memory for quick access.
New Data from online storage is often transferred to offline storage so the model can be trained on it. This is called feature ingestion.
So, if a prediction needs to be made, the model will read the online feature store to get data.
If many predictions need to be made from different users that require lots of feature data, thousands or tens of thousands of reads could be made simultaneously.
How DoorDash Improved Redis
Without modifications, Redis can handle a few hundred thousand reads per second. Which is more than enough for the average company.
But for DoorDash to use it as its feature store, it needed to handle a few million reads per second, which it struggled with.
So to improve Redis, the team needed to make it use less memory and use the CPU more efficiently. These were some of the bottlenecks they encountered.
Let's go through how they did that.
The first thing they did was to use Redis Hashes.
Sidenote: Redis Hashes
Redis Hashes are a data structure that allows you to store many values with a single key.
By default, Redis uses strings to store values, which weren't designed for many related values.

But hashes are designed to do that. They are more memory efficient for storing many values because Redis can optimize them.

You could also use the HGET command to get a single value and HMGET to get multiple values.

Hashes alone reduced CPU usage by 82%. But there were more optimizations the team could make.
Next, they compressed feature names and values.
They compressed feature names with a fast hashing algorithm called xxHash.
Feature names were typically very long for human readability.
But they took up 27 bytes of memory. Putting that exact text through xxHash would reduce it to 32 bits.
Considering 27 bytes (B) is 216 bits (b), that's an 85% reduction in size. Doing this on a large scale reduced a lot of memory.

The team likely had a separate mapping or table that linked each feature name to the hashed feature name.
When it came to compressing feature values, they used a more complicated approach.
They first converted values to Protocol buffers (protobufs). A data format developed by Google to store and transmit data in a compact form. It is a way to convert structured data to a binary format and is heavily used in gRPC.
Then, they compressed the protobufs using Snappy. Another Google-developed library that focuses on speed over compression size.

Snappy doesn't have the highest compression ratio and doesn't have the lowest CPU usage. But it was chosen over other options because it could compress Redis hashes and decompress feature values well.

With all these changes, DoorDash saw a 62% reduction in overall memory usage, from 298 GB of RAM to 112GB.
And a 65% reduction in CPU use from 208 CPUs to 72 per 10 million reads per second.
That’s incredible.
Wrapping things up
If you thought the efforts of the DoorDash team weren't impressive enough, check this out.
They added CockroachDB to their feature store because Redis' memory costs were too high.
They used CockroachDB as an offline feature store and kept Redis as their online feature store. But that's a topic for another article.
As usual, if you liked this post and want more details, check out the original article.
And if you want the next article sent straight to your inbox, be sure to subscribe.
PS: Enjoyed this newsletter? Please forward it to a pal or follow us on socials (LinkedIn, Twitter, YouTube, Instagram). It only takes 10 seconds. Making this one took 22 hours.