
How Discord Processes 30+ Petabytes of Data
Discord's genius approach to automating insights from billions of messages

Discord is a well-known chat app like Slack, but it was originally designed for gamers.
Today it has a much broader audience and is used by millions of people every day—29 million, to be exact.
Like many other chat apps, Discord stores and analyzes every single one of its 4 billion daily messages.
Let's go through how and why they do that.
Estimated reading time: 4 minutes 56 seconds
Why Does Discord Analyze Your Messages?
Reading the opening paragraphs you might be shocked to learn that Discord stores every message, no matter when or where they were sent.
Even after a message is deleted, they still have access to it.
Here are a few reasons for that:
Identify bad communities or members: scammers, trolls, or those who violate their Terms of Service.
Figuring out what new features to add or how to improve existing ones.
Training their machine learning models. They use them to moderate content, analyze behavior, and rank issues.
Understanding their users. Analyzing engagement, retention, and demographics.
There are a few more reasons beyond those mentioned above. If you're interested, check out their Privacy Policy.
But, don't worry. Discord employees aren't reading your private messages. The data gets anonymized before it is stored, so they shouldn't know anything about you.
And for analysis, which is the focus of this article, they do much more.
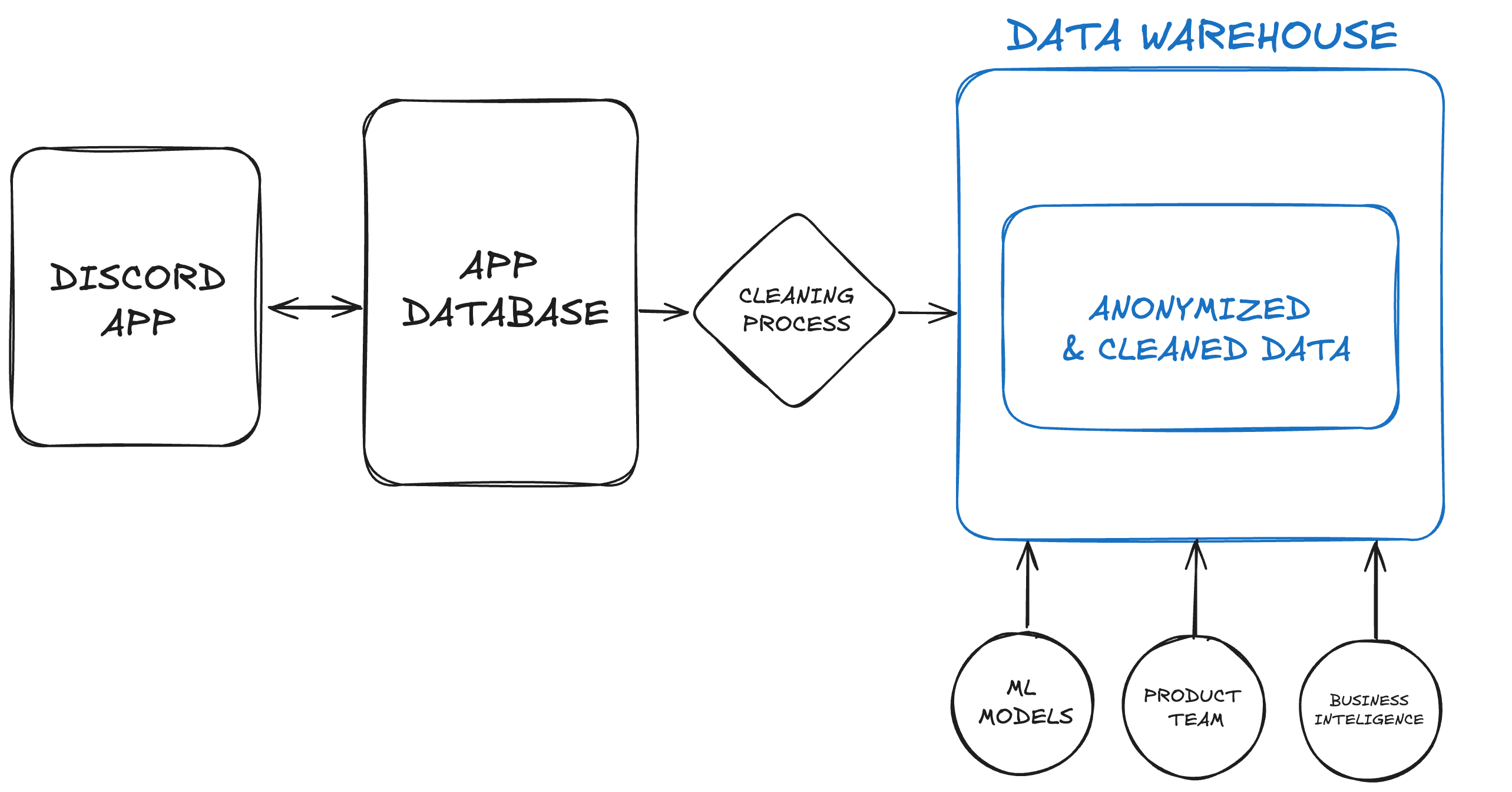
When a user sends a message, it is saved in the application-specific database, which uses ScyllaDB.
This data is cleaned before being used. We’ll talk more about cleaning later.
But as Discord began to produce petabytes of data daily.
Yes, petabytes (1,000 terabytes)—the business needed a more automated process.
They needed a process that would automatically take raw data from the app database, clean it, and transform it to be used for analysis.
This was being done manually on request.
And they needed a solution that was easy to use for those outside of the data platform team.
This is why they developed Derived.
Sidenote: ScyllaDB
Scylla is a NoSQL database written in C++ and designed for high performance.
NoSQL databases don't use SQL to query data. They also lack a relational model like MySQL or PostgreSQL.
Instead, they use a different query language. Scylla uses CQL, which is the Cassandra Query Language used by another NoSQL database called Apache Cassandra.
Scylla also shards databases by default based on the number of CPU cores available.
For example, an M1 MacBook Pro has 10 CPU cores. So a 1,000-row database will be sharded into 10 databases containing 100 rows each. This helps with speed and scalability.
Scylla uses a wide-column store (like Cassandra). It stores data in tables with columns and rows. Each row has a unique key and can have a different set of columns.
This makes it more flexible than traditional rows, which are determined by columns.

What is Derived?
You may be wondering, what's wrong with the app data in the first place? Why can't it be used directly for analysis?
Aside from privacy concerns, the raw data used by the application is designed for the application, not for analysis.
The data has information that may not help the business. So, the cleaning process typically removes unnecessary data before use. This is part of a process called ETL. Extract, Transform, Load.
Discord used a tool called Airflow for this, which is an open-source tool for creating data pipelines. Typically, Airflow pipelines are written in Python.
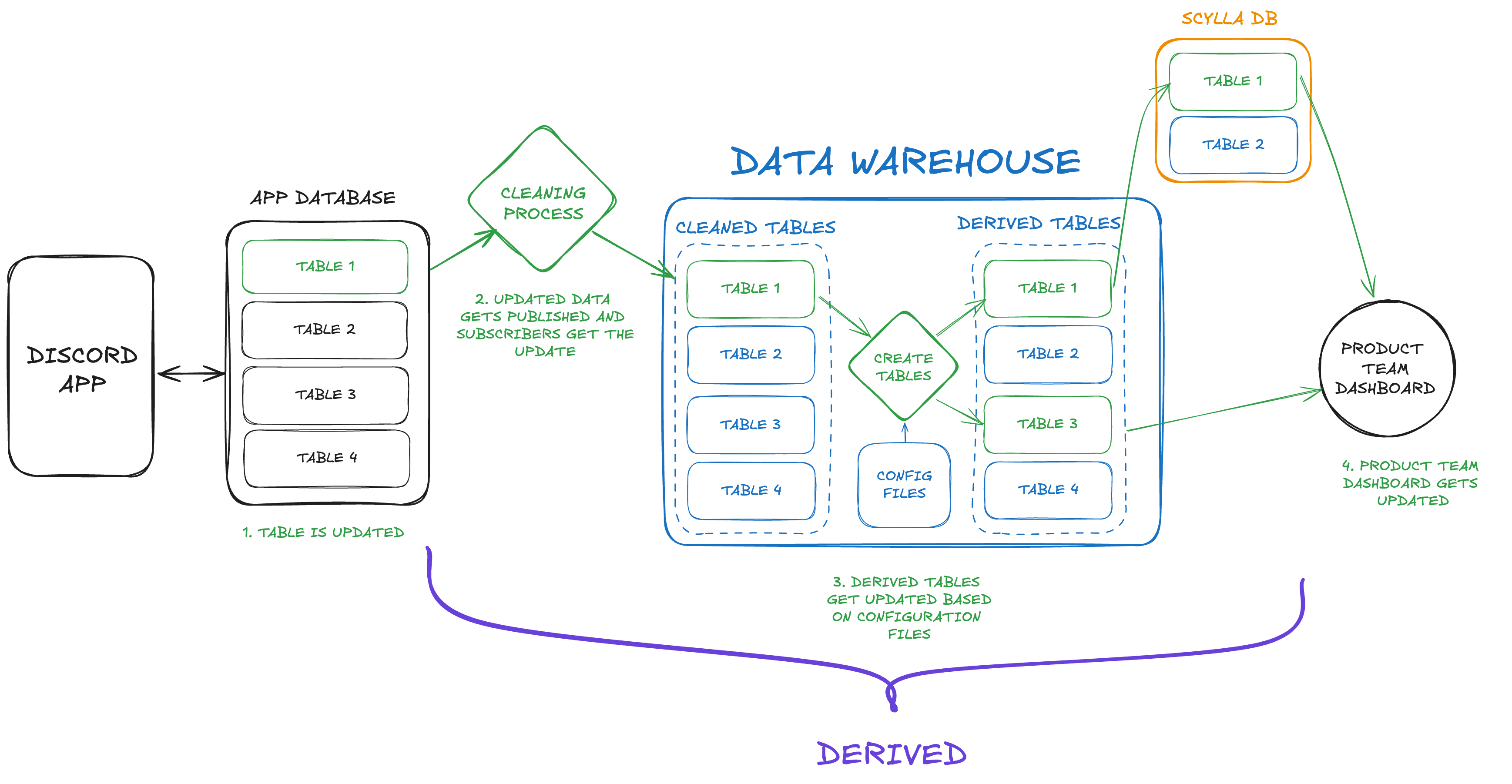
The cleaned data for analysis is stored in another database called the Data Warehouse.
Temporary tables created from the Data Warehouse are called Derived Tables.
This is where the name "Derived" came from.
Sidenote: Data Warehouse
You may have figured this out based on the article, but a data warehouse is a place where the best quality data is stored.
This means the data has been cleaned and transformed for analysis.
Cleaning data means anonymizing it. So remove personal info and replace sensitive data with random text. Then remove duplicates and make sure things like dates are in a consistent format.
A data warehouse is the single source of truth for all the company's data, meaning data inside it should not be changed or deleted. But, it is possible to create tables based on transformations from the data warehouse.
Discord used Google's BigQuery as their data warehouse, which is a fully managed service used to store and process data.
It is a service that is part of Google Cloud Platform, Google's version of AWS.
Data from the Warehouse can be used in business intelligence tools like Looker or Power BI. It can also train machine learning models.
Before Derived, if someone needed specific data like the number of daily sign ups. They would communicate that to the data platform team, who would manually write the code to create that derived table.
But with Derived, the requester would create a config file. This would contain the needed data, plus some optional extras.
This file would be submitted as a pull request to the repository containing code for the data transformations. Basically a repo containing all the Airflow files.
Then, a continuous integration process, something like a GitHub Action, would create the derived table based on the file.
One config file per table.
This approach solved the problem of the previous system not being easy to edit by other teams.
To address the issue of data not being updated frequently enough, they came up with a different solution.
The team used a service called Cloud Pub/Sub to update data warehouse data whenever application data changed.
Sidenote: Pub/Sub
Pub/Sub is a way to send messages from one application to another.
"Pub" stands for Publish, and "Sub" stands for Subscribe.
To send a message (which could be any data) from app A to app B, app A would be the publisher. It would publish the message to a topic.
A topic is like a channel, but more of a distribution channel and less like a TV channel. App B would subscribe to that topic and receive the message.
Pub/Sub is different from request/response and other messaging patterns. This is because publishers don’t wait for a response before sending another message.
And in the case of Cloud Pub/Sub, if app B is down when app A sends a message, the topic keeps it until app B is back online.
This means messages will never be lost.
This method was used for important tables that needed frequent updates. Less critical tables were batch-updated every hour or day.
The final focus was speed. The team copied frequently used tables from the data warehouse to a Scylla database. They used it to run queries, as BigQuery isn't the fastest for that.
With all that in place, this is what the final process for analyzing data looked like:
Wrapping Things Up
This topic is a bit different from the usual posts here. It's more data-focused and less engineering-focused. But scale is scale, no matter the discipline.
I hope this gives some insight into the issues that a data platform team may face with lots of data.
As usual, if you want a much more detailed account, check out the original article.
If you would like more technical summaries from companies like Uber and Canva, go ahead and subscribe.
PS: Enjoyed this newsletter? Please forward it to a pal or follow us on socials (LinkedIn, Twitter, YouTube, Instagram). It only takes 10 seconds. Making this one took 25 hours.