
Figma's 100x Approach to Scaling Its Collaborative Experience
How Figma destroyed their old setup and used the pieces to build a better one

Figma is a web-based design tool. It’s great for creating user interfaces for websites, mobile apps, and similar projects.
What makes it so unique is its amazing collaboration features.
Users can work on the same file simultaneously. Seeing exactly what everyone is doing as they edit and comment.
This is one reason Figma has 4 million active users. And also why they focus on making collaboration fast, even as their user base grows.
They do this in many ways, but one important way is by developing a system called LiveGraph.
Estimated reading time: 4 minutes 40 seconds
LiveGraph?
When Figma first launched its collaboration feature back in 2016, it ran on a simple tech stack.
React on the frontend, Ruby on the backend. Redux for state management, and WebSockets for real-time communication.
Collaboration worked like this. When a client changed something, like renaming a file. The database was updated. And then that event was broadcasted to other clients.
Events were hand-coded. The process was time-consuming and became complicated as Figma added more features.
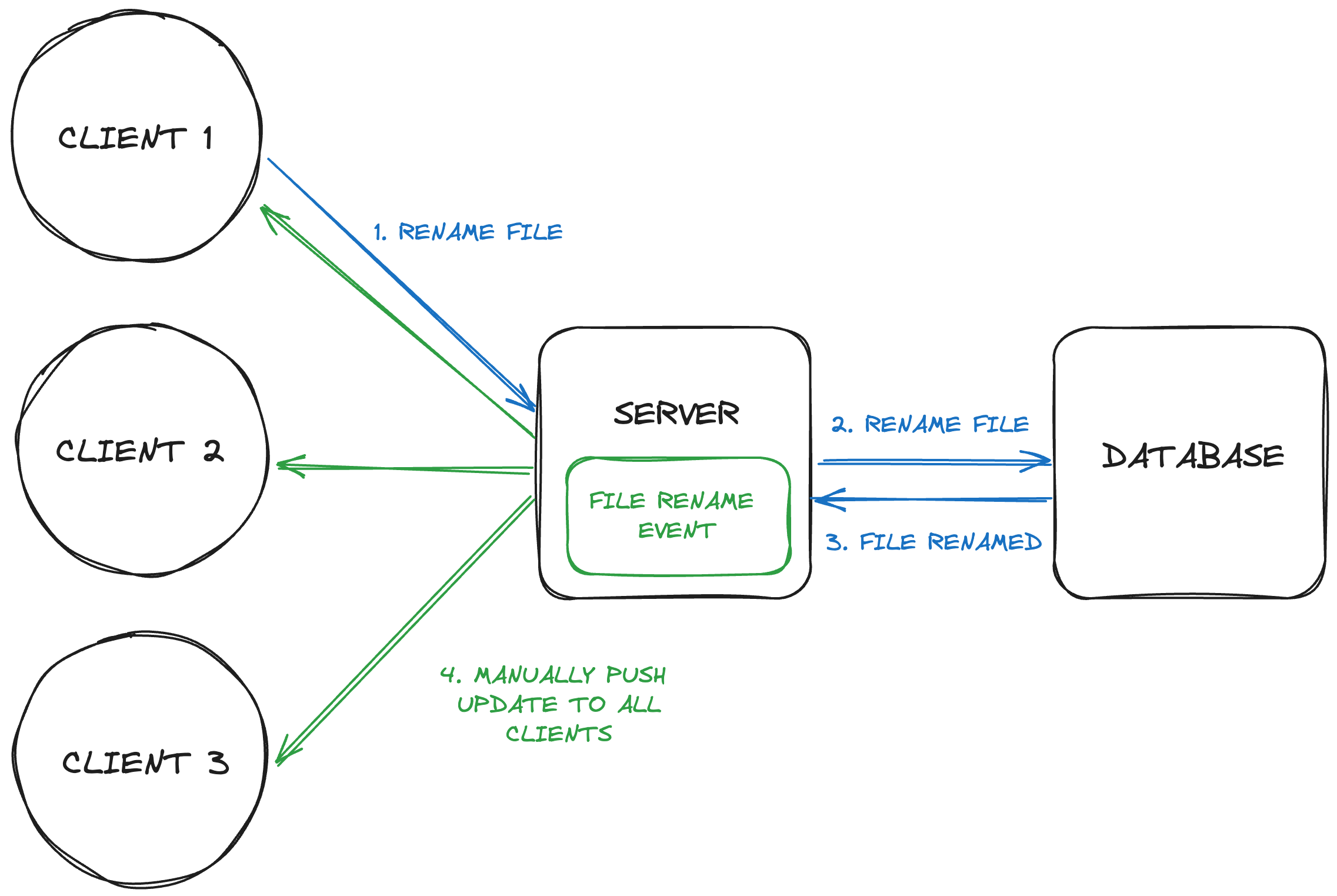
This is why LiveGraph was created.
It was inspired by GraphQL, built in-house, and serves as a data store or cache for all clients. It also manages database queries and updates.
This means that instead of having to manually write an event to broadcast. Clients subscribe to LiveGraph.
So clients know whenever something changes. Like subscribing to a newsletter or your favorite YouTube channel.

This approach was easier to manage.
Sidenote: GraphQL
GraphQL is a query language that makes it easy to request data from a server.
The reason for using it over REST is simple. With REST, you need many endpoints to get different data. With this, you can write a single endpoint to get all the data you need.
Using JSON-like syntax for the query, a single or many HTTP POST requests are made to the server.
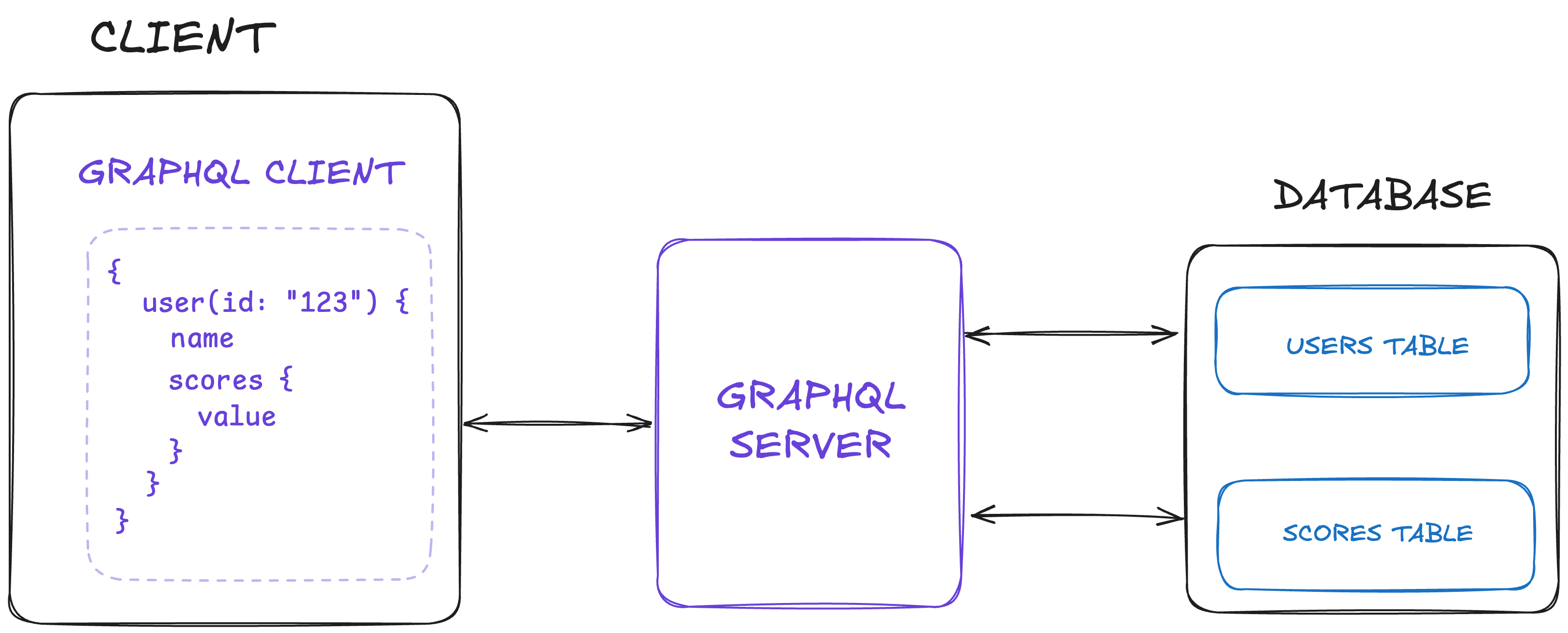
With GraphQL however, it's difficult to get real-time updates, especially with event streams.
This is why Figma built LiveGraph.
Problems with LiveGraph
LiveGraph worked well for the user base Figma had at the time. But since its release, Figma users tripled and page views increased by 5x.
This all ran on a single Postgres database which had tables several terabytes in size.
A technique called sharding solved this giving the database near-infinite scalability.
LiveGraph wasn't designed for such a large database; it also needed to be scaled.
This started a project called LiveGraph 100x.
This article will focus on two techniques Figma used to scale LiveGraph.
Improving caching
Creating an invalidator.
Sidenote: Sharding
For most projects, it's perfectly fine to have a single database.
But for databases with millions or even billions of rows, a single database would consume lots of resources.
Sharding is a way to split a large database into smaller databases, each containing a subset of the data.
There is horizontal sharding, which splits the database by rows. And there is vertical sharding, which splits it by columns.
Figma implemented a horizontal sharding solution.
As a simple example, if a database had 1,000 rows, it could be sharded into 10 databases, each containing 100 rows.
Improving The Caching
The obvious first step to scaling LiveGraph was to increase its number of instances. This would allow the workload to be shared.
The problem with this is that it would create many caches. The database wouldn't know which cache requested the data, so it would send the data to all of them.

To solve this, the cache was taken out and moved to a single centralized cache.
Now all LiveGraph instances would use one cache. And data would go to the same place.

But this raised another issue.
The large number of users and their Figma activities could make the cache very large.
So they decided to shard the cache, just as they did with the database.
The cache was a key-value store containing the query as the key and the results as the value. Sharding worked by hashing the key, then storing both the key and the value.
This meant a LiveGraph instance would only use its needed cache shards, not the entire cache.

But this solution introduces two problems.
The database wouldn't know which cache shard to send the data to.
Changing one shard might require changes to another shard.
For example, if a file is moved to a different folder, two shards would need to be updated. The shard that stores files from the old folder and the shard that stores files from the new folder.
To solve these problems, the team created an Invalidator.
Sidenote: Hashing
Hashing is the process of converting data into a fixed-length of letters and numbers.
As a simple example, imagine we want to hash the word "hello."
We could take the position of each letter in the alphabet, then add them all together. So "hello" would become 52.
Of course, modern hashing algorithms are much more complex.
Using the MD5 algorithm, "hello" would be:
5d41402abc4b2a76b9719d911017c592.Hashing is very fast. It provides a unique ID for data, and the same input with the same algorithm will always produce the same output.
They are commonly used to store passwords and create indexes for things like databases.
Creating an Invalidator
The system now has many cache shards. A Figma user typically only uses a specific part of the app at a time. So a LiveGraph instance doesn't need to subscribe to all the shards.
But sometimes an update in one shard would trigger a different shard to update. And if LiveGraph isn't subscribed to a shard, it wouldn't display the update.
Think back to the file moving example.

To save resources, instead of automatically updating shards, they were marked as invalid.
Meaning if in the future, a LiveGraph instance subscribes to an invalid shard. It knows it needs to get updated data from the database.
The job of the invalidator was to mark the correct shards as invalid.
It was a server that was sharded like the database. And worked by reading the logs of that specific database shard.
It would then figure out what cache shards to mark as invalid based on mutations in the DB.
With both cache sharding and invalidators in place, here is the new LiveGraph.

It is truly impressive how the engineering team at Figma came up with these solutions.
Wrapping Things Up
It's important to remember that Figma built all these technologies in-house. This means there are a lot of details not covered in this article; for example,
Specifics of subscribing to cache shards.
How the invalidator creates queries by comparing data before and after a change.
And how queries are routed to the correct database or cache shard.
This is all covered in the original article. As well as a database scaling article and a talk given by one of Figma's engineers.
But if you're satisfied with this information and can't wait for the next one. Go ahead and subscribe.
PS: Enjoyed this newsletter? Please forward it to a pal or follow us on socials (LinkedIn, Twitter, YouTube, Instagram). It only takes 10 seconds. Making this one took 25 hours.