
How Stripe Processed $1 Trillion in Payments with Zero Downtime
Stripe's hand-crafted system that guarantees their data never gets lost

Stripe is a platform that allows businesses to accept payments online and in person.
Yes, there are lots of other payment platforms like PayPal and Square. But what makes Stripe so popular is its developer-friendly approach.
It can be set up with just a few lines of code, has excellent documentation and support for lots of programming languages.
Stripe is now used on 2.84 million sites and processed over $1 trillion in total payments in 2023. Wow.
But what makes this more impressive is they were able to process all these payments with virtually no downtime.
Here's how they did it.
Estimated reading time: 4 minutes 58 seconds.
The Resilient Database
When Stripe was starting out, they chose MongoDB because they found it easier to use than a relational database.
But as Stripe began to process large amounts of payments. They needed a solution that could scale with zero downtime during migrations.
MongoDB already has a solution for data at scale which involves sharding. But this wasn't enough for Stripe's needs.
Sidenote: MongoDB Sharding
Sharding is the process of splitting a large database into smaller ones. This means all the demand is spread across smaller databases.
Let's explain how MongoDB does sharding. Imagine we have a database or collection for users.
Each document has fields like userID, name, email, and transactions.
Before sharding takes place, a developer must choose a shard key. This is a field that MongoDB uses to figure out how the data will be split up. In this case, userID is a good shard key.
If userID is sequential, we could say users 1-100 will be divided into a chunk. Then, 101-200 will be divided into another chunk, and so on. The max chunk size is 128MB.
From there, chunks are distributed into shards, a small piece of a larger collection.

MongoDB creates a replication set for each shard. This means each shard is duplicated at least once in case one fails. So, there will be a primary shard and at least one secondary shard.
It also creates something called a Mongos instance, which is a query router. So, if an application wants to read or write data, the instance will route the query to the correct shard.
A Mongos instance works with a config server, which keeps all the metadata about the shards. Metadata includes how many shards there are, which chunks are in which shard, and other data.

Stripe wanted more control over all this data movement or migrations. They also wanted to focus on the reliability of their APIs.
So, the team built their own database infrastructure called DocDB on top of MongoDB.
MongoDB managed how data was stored, retrieved, and organized. While DocDB handled sharding, data distribution, and data migrations.
Here is a high-level overview of how it works.

Aside from a few things the process is similar to MongoDB's. One difference is that all the services are written in Go to help with reliability and scalability.
Another difference is the addition of a CDC. We'll talk about that in the next section.
The Data Movement Platform
The Data Movement Platform is what Stripe calls the 'heart' of DocDB. It's the system that enables zero downtime when chunks are moved between shards.
But why is Stripe moving so much data around?
DocDB tries to keep a defined data range in one shard, like userIDs between 1-100. Each chunk has a max size limit, which is unknown but likely 128MB.
So if data grows in size, new chunks need to be created, and the extra data needs to be moved into them.
Not to mention, if someone wants to change the shard key for a more even data distribution. Then, a lot of data would need to be moved.
This gets really complex if you take into account that data in a specific shard might depend on data from other shards.
For example, if user data contains transaction IDs. And these IDs link to data in another collection.
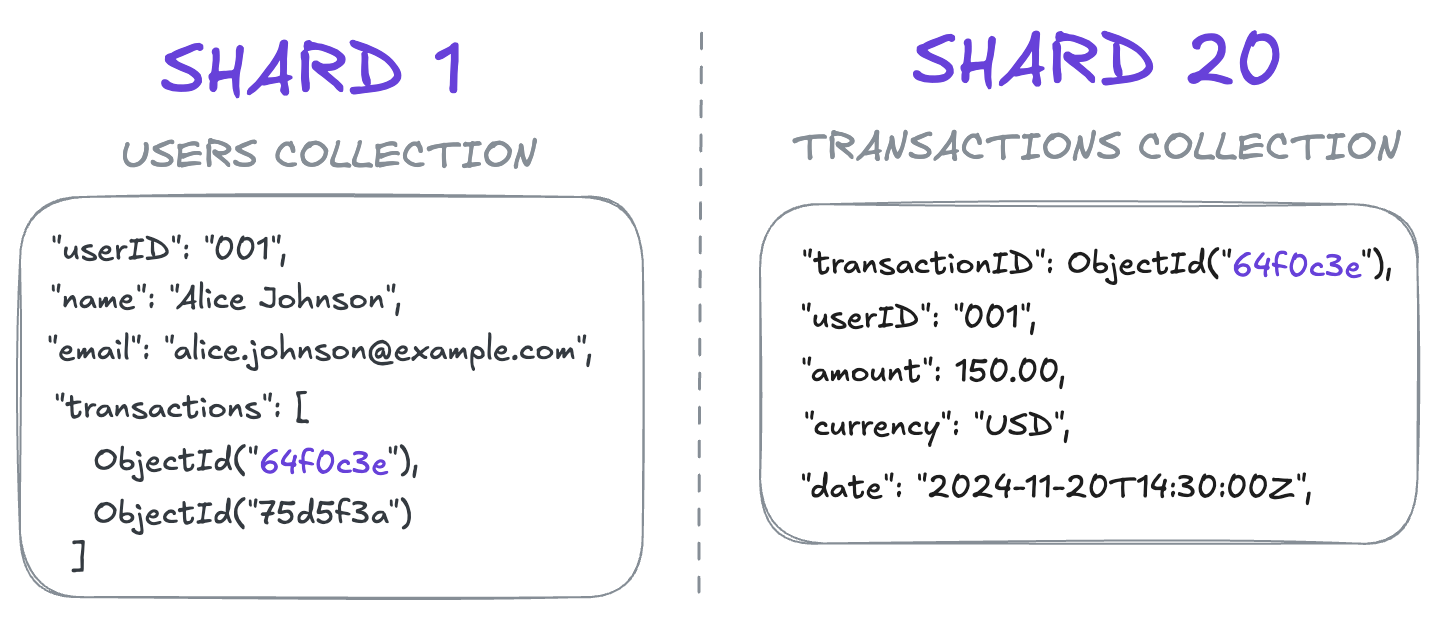
If a transaction gets deleted or moved, then chunks in different shards need to change.
These are the kinds of things the Data Movement Platform was created for.
Here is how a chunk would be moved from Shard A to Shard B.

1. Register the intent. Tell Shard B that it's getting a chunk of data from Shard A.
2. Build indexes on Shard B based on the data that will be imported. An index is a small amount of data that acts as a reference. Like the contents page in a book. This helps the data move quickly.
3. Take a snapshot. A copy or snapshot of the data is taken at a specific time, we'll call this T.
4. Import snapshot data. The data is transferred from the snapshot to Shard B. But during the transfer, the chunk on Shard A can accept new data. Remember, this is a zero-downtime migration.
5. Async replication. After data has been transferred from the snapshot, all the new or changed data on Shard A after T is written to Shard B.
But how does the system know what changes have taken place? This is where the CDC comes in.
Sidenote: CDC
Change Data Capture, or CDC, is a technique that is used to capture changes made to data. It's especially useful for updating different systems in real-time.
So when data changes, a message containing before and after the change is sent to an event streaming platform, like Apache Kafka. Anything subscribed to that message will be updated.

In the case of MongoDB, changes made to a shard are stored in a special collection called the Operation Log or Oplog. So when something changes, the Oplog sends that record to the CDC.
Different shards can subscribe to a piece of data and get notified when it's updated. This means they can update their data accordingly.
Stripe went the extra mile and stored all CDC messages in Amazon S3 for long term storage.
6. Point-in-time snapshots. These are taken throughout the async replication step. They compare updates on Shard A with the ones on Shard B to check they are correct.
Yes, writes are still being made to Shard A so Shard B will always be behind.
7. The traffic switch. Shard A stops being updated while the final changes are transferred. Then, traffic is switched, so new reads and writes are made on Shard B.
This process takes less than two seconds. So, new writes made to Shard A will fail initially, but will always work after a retry.
8. Delete moved chunk. After migration is complete, the chunk from Shard A is deleted, and metadata is updated.
Wrapping Things Up
This has to be the most complicated database system I have ever seen.
It took a lot of research to fully understand it myself. Although I'm sure I'm missing out some juicy details.
If you're interested in what I missed, please feel free to run through the original article.
And as usual, if you enjoy reading about how big tech companies solve big issues, go ahead and subscribe.
PS: Enjoyed this newsletter? Please forward it to a pal or follow us on socials (LinkedIn, Twitter, YouTube, Instagram). It only takes 10 seconds. Making this one took 20 hours.