
How LinkedIn Reduced GPU Memory Usage by 60% for LLM Training
LinkedIn hand-picked the best GPU performance techniques and put them in a library

LinkedIn uses large language models (LLMs) for many features, just like other tech companies. Features like job matching and providing users with relevant content.
But, LinkedIn has so much data that training these models takes up a huge amount of resources.
So the team found a way to make that process more efficient.
Here's how they did it.
Estimated reading time 5 minutes and 15 seconds.
Why Is Training So Resource Intensive?
Training a model involves giving it a large amount of data to learn from.
There are three steps that can be done for training:
Pre-training: Teaching the model general language
Fine-tuning: Specializing the model for specific tasks
Alignment: Making sure the model behaves as intended, this step is optional
Pre-training is the most resource-intensive step, so we'll focus on that.
This involves giving the model large unstructured data like books, articles, and websites. The data is stored in text, JSON, or binary format.
Then, words are tokenized into a numerical representation. So a sentence like "I love programming" could be represented as [1, 23, 456]
These tokens are converted to embeddings, which capture words or phrases in a dense numerical format. This helps the model understand their meaning and relationship to other words.
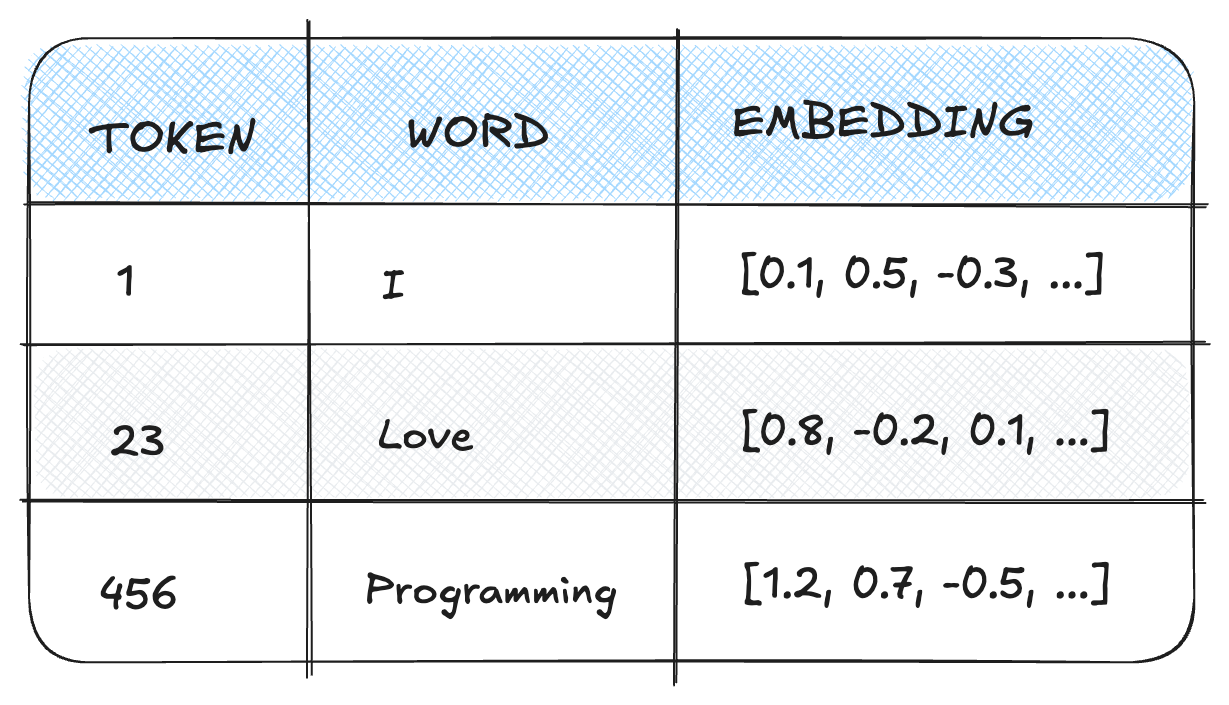
After that, the training phase starts.
Here, the model learns patterns by predicting the next word in a sentence or guessing missing words. This is all done automatically (self-supervised).
The model has the answers, so it tries to predict the answer and then checks it against the correct sentence. If it's correct or incorrect, it adjusts its weights to reduce the chances of a wrong prediction (backpropagation).
A complete pass through all the data is called an epoch. But training usually stops after many epochs. At least one, but it could be up to 300.
To speed things up, predictions are made in parallel using lots of GPUs. But even so, training a model on gigabytes of data through many epochs could take days or weeks.

Sidenote: Model Weights
An LLM is made up of many nodes. These process data from inputs.
Nodes are organized into layers to process data in stages. A weight is the strength of the connection between nodes on different layers.
Weights are randomly assigned numbers at the start of training. But they change during training to produce better outputs.
For example, if you're training a model to recognize the positivity of the sentence, “Get lost”. The inputs would be the word embeddings, and the weight value could lean towards positivity. So, the higher the value, the more positive the output.
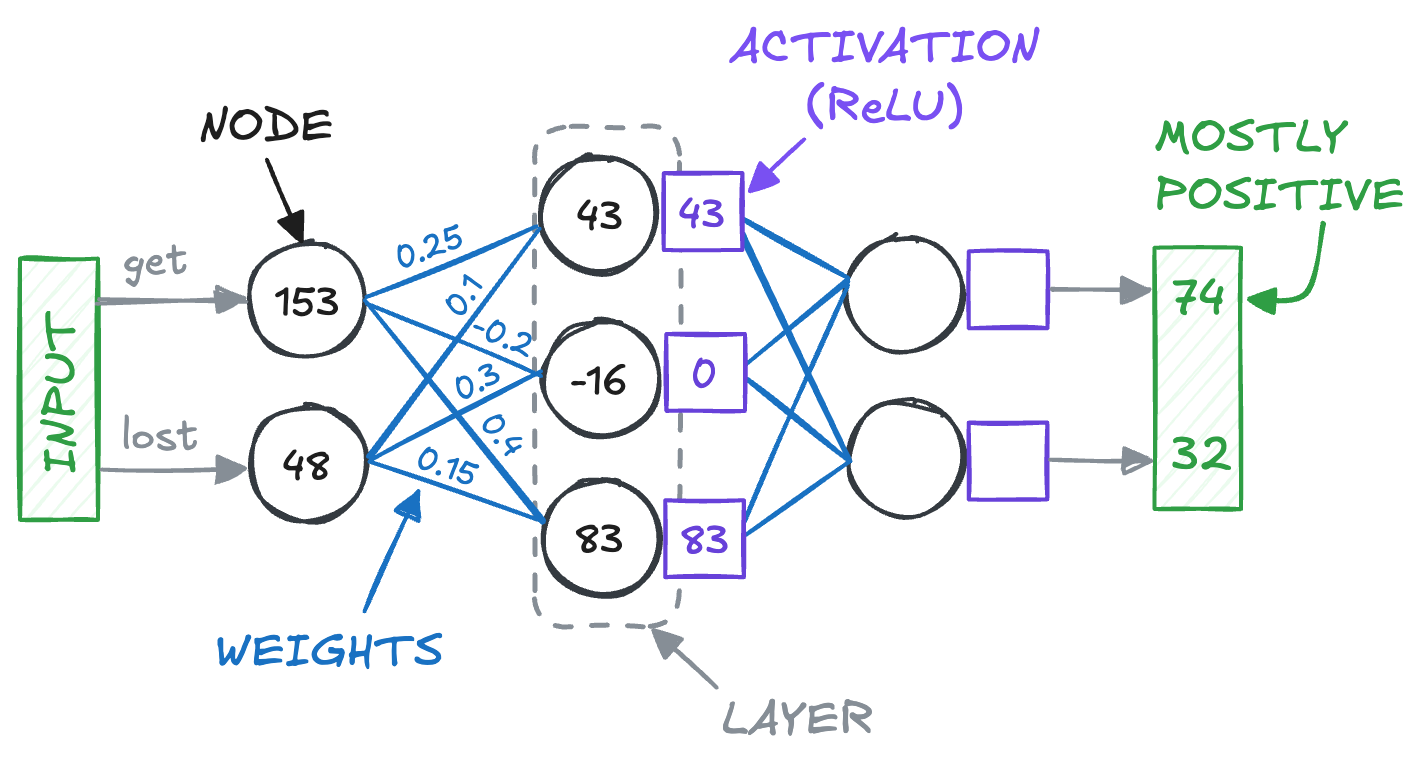
A node typically has more than one weight. So, all weight values are summed and then go through an activation function. This adds 'non-linearity' to the values, which helps the model learn complex patterns.

In LinkedIn’s case, they were experiencing performance bottlenecks during training, such as:
Heavy GPU memory access
Extra time and resources used per-operation
To address this, they built a library called Liger-Kernel.
Liger-Kernel to the Rescue
Let's jump into how Liger-Kernel addressed these bottlenecks. We'll start with GPU memory access.
The GPU has different memory types for different purposes during training.
Slower High Bandwidth Memory (HBM) stores datasets, weights, and other large data structures.
Faster Shared Memory (SRAM) stores frequently accessed data. This could be intermediate calculations such as attention scores.
Because the SRAM is small, data is regularly transferred between the HBM and SRAM. This can add latency and delay computation time.

Sidenote: Attention Scores
A way for the model to "pay attention" to the most relevant parts of the input data.
Let's take a look at these two sentences:
"Jason is much faster than Toby; he trains a lot."
"Jason is much faster than Toby, who trains a lot."
The sentences only have one different word, which completely changes their meaning. The 'trains a lot' in the first sentence is for Jason, and the second is for Toby. We humans can figure out this instantly, but a model can't.

What we see as words, models see as lots of numbers. So, attention scores exist to focus on the important parts.
In the case of the first sentence, "Jason", "he", "trains a lot", and the semicolon could have higher attention scores. This is because the semicolon indicates a new clause that refers to Jason. This means Jason is faster because he trains a lot.
For the second sentence. "Toby" and "who trains a lot" could have a higher attention score because "trains a lot" relates to Toby. This suggests Toby is the one who trains, but Jason is still faster.

Liger-Kernel is built upon a technique called FlashAttention. This can improve GPU performance by calculating things like attention scores and partial sums on the SRAM instead of the HBM.
This was a good first step. But, they further optimized GPUs by taking tasks that needed many GPUs and merging operations so tasks could run on one GPU.
This is one of the ways they dealt with the per-operation time bottleneck.
Let's explain it with an example.
Two operations are used to control the range of values during training:
RMSNorm: Root Mean Square Normalization. A technique used to normalize the size (magnitude) of activation outputs from a layer of nodes.
Scaling: Adjust the range or magnitude of input data to a common scale. This helps the learning process because scaling makes sure data is within a range that the model can learn from.
Typically, these operations are performed on different GPUs. But they can be merged together (operator fusion). How?
Training can be done with a framework like PyTorch or TensorFlow. Out of the box, PyTorch does something called eager execution. This means operations are executed immediately without a compilation step.
While it sounds good in theory, it has some performance issues. Since operations are executed one at a time (synchronously), this prevents parallel executions.
To address this, PyTorch introduced a feature called torch.compile. Which enables Just-In-Time (JIT) compilation. JIT compiles a models' computational graph to machine code for faster execution.
A computation graph represents the sequence of operations a model performs on its inputs to produce an output.
Part of JIT involves operator fusion for many operations, not just the two mentioned earlier. In some cases JIT can be 22 times faster than eager execution.
Both FlashAttention and operator fusion work in Liger-Kernel. These features addressed the bottlenecks LinkedIn had.
But Liger-Kernel is a Python library, and raw Python code cannot run on a GPU.
So they wrote it in a language called Triton.
Python on the GPU
Triton is an open source domain-specific language and compiler created by an OpenAI employee. It's designed to help write custom GPU kernels using a Python-based syntax.
Triton code complies to low-level GPU code that generates a new optimized GPU kernel.
LinkedIn wrote their own operator fusion in Triton for Liger-Kernel. But also wrote RMSNorm and other operations in Triton to take full advantage of the GPU.
So, how is Liger-Kernel deployed?
Usually training is done through a distributed setup. This involves many GPUs training different parts of the model.
There are many distributed setups, but we'll focus on Torch Distributed Elastic in AWS purely because AWS diagrams make sense to me.

This has a parameter server used to store and update parameters like weights. And a controller to manage training jobs based on the available resources.
Liger-Kernel will be added to the container image, which runs on a pod. Once the pod starts, Liger-Kernel code compiles then optimizes the GPU kernel before training begins.
With all these features and optimized post-training losses, which I won't go into in this article. LinkedIn's open-source library has achieved impressive performance.
Improved multi-GPU training throughput by 20%. A 3x reduction in end-to-end training time. Reduced memory usage by 60% and much more.
If you enjoyed this article, check out the original article from LinkedIn.
PS: Enjoyed this newsletter? Please forward it to a pal or follow us on socials (LinkedIn, Twitter, YouTube, Instagram). It only takes 10 seconds. Making this one took 20 hours.