
How GitHub Reduced Repo Storage Size by Over 90%
GitHub tackled its data overload by introducing a completely new type of file

GitHub supports over 200 programming languages and has over 330 million repositories. But it has a pretty big problem.
It stores almost 19 petabytes of data.
You can store 3 billion songs with one petabyte, so we're talking about a lot of data.
And much of that data is unreachable; it's just taking up space unnecessarily.
But with some clever engineering, GitHub was able to fix that and reduce the size of specific projects by more than 90%.
Here's how they did it.
Estimated reading time: 4 minutes 25 seconds.
Why GitHub has Unreachable Data
The Git in GitHub comes from the name of a version control system called Git, which was created by the founder of Linux.
It works by tracking changes to files in a project over time using different methods.
A developer typically installs Git on their local machine. Then, they push their code to GitHub, which has a custom implementation of Git on its servers.
Although Git and GitHub are different products, the GitHub team adds features to Git from time to time.
So, how does it track changes? Well, every piece of data Git tracks is stored as an object.
Sidenote: Git Objects and Branches
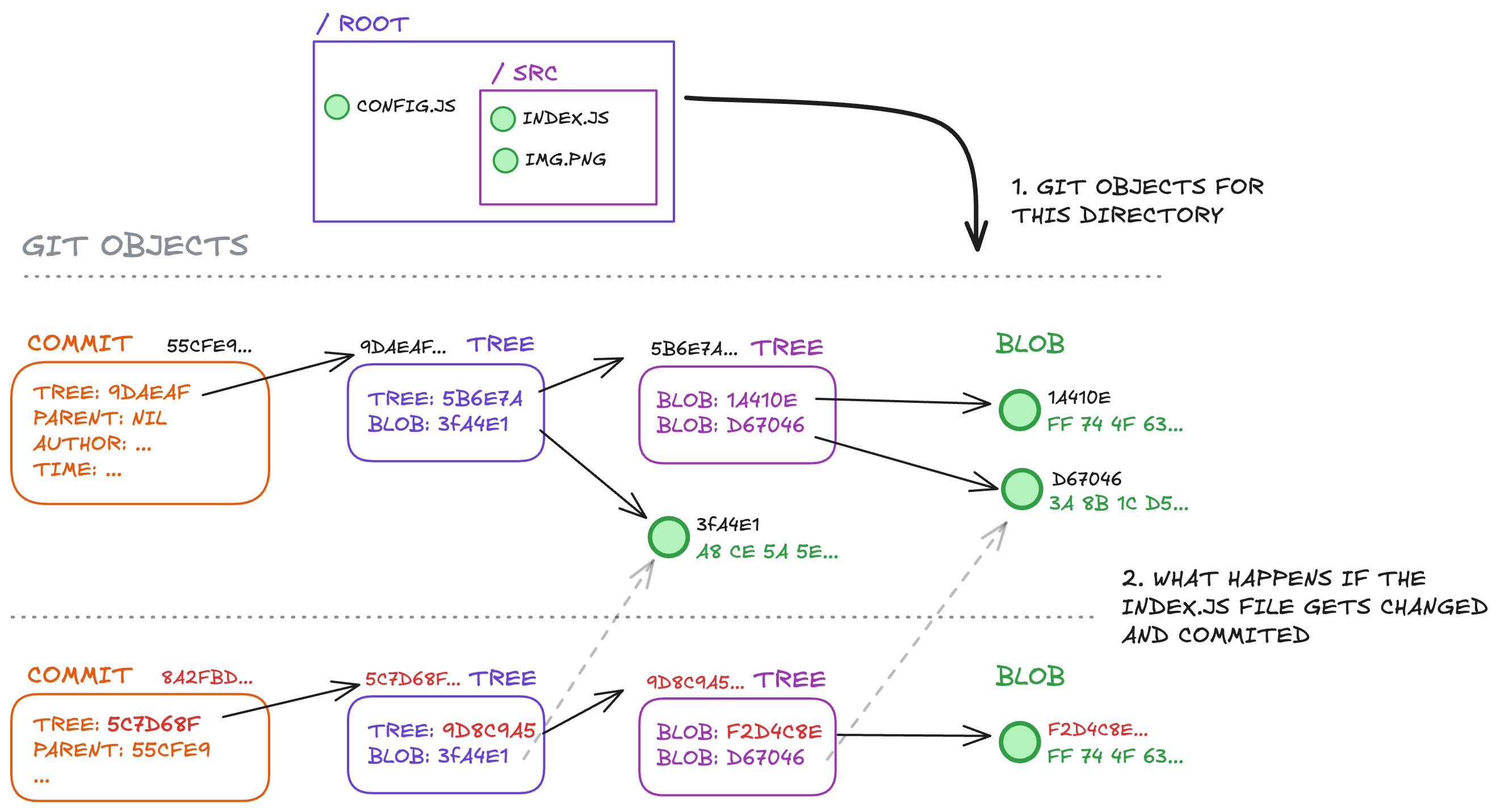
A Git object is something Git uses to keep track of a repository's content over time.
There are three main types of objects in Git.
1. BLOB - Binary large object. This is what stores the contents of a file, not the filename, location, or any other metadata.
2. Tree - How Git represents directories. A tree lists blobs and other trees that exist in a directory.
3. Commit - A snapshot of the files (blobs) and directories (trees) at a point in time. It also contains a parent commit, a hash of the previous commit.
A developer manually creates a commit containing hashes of just the blobs and trees that have changed.
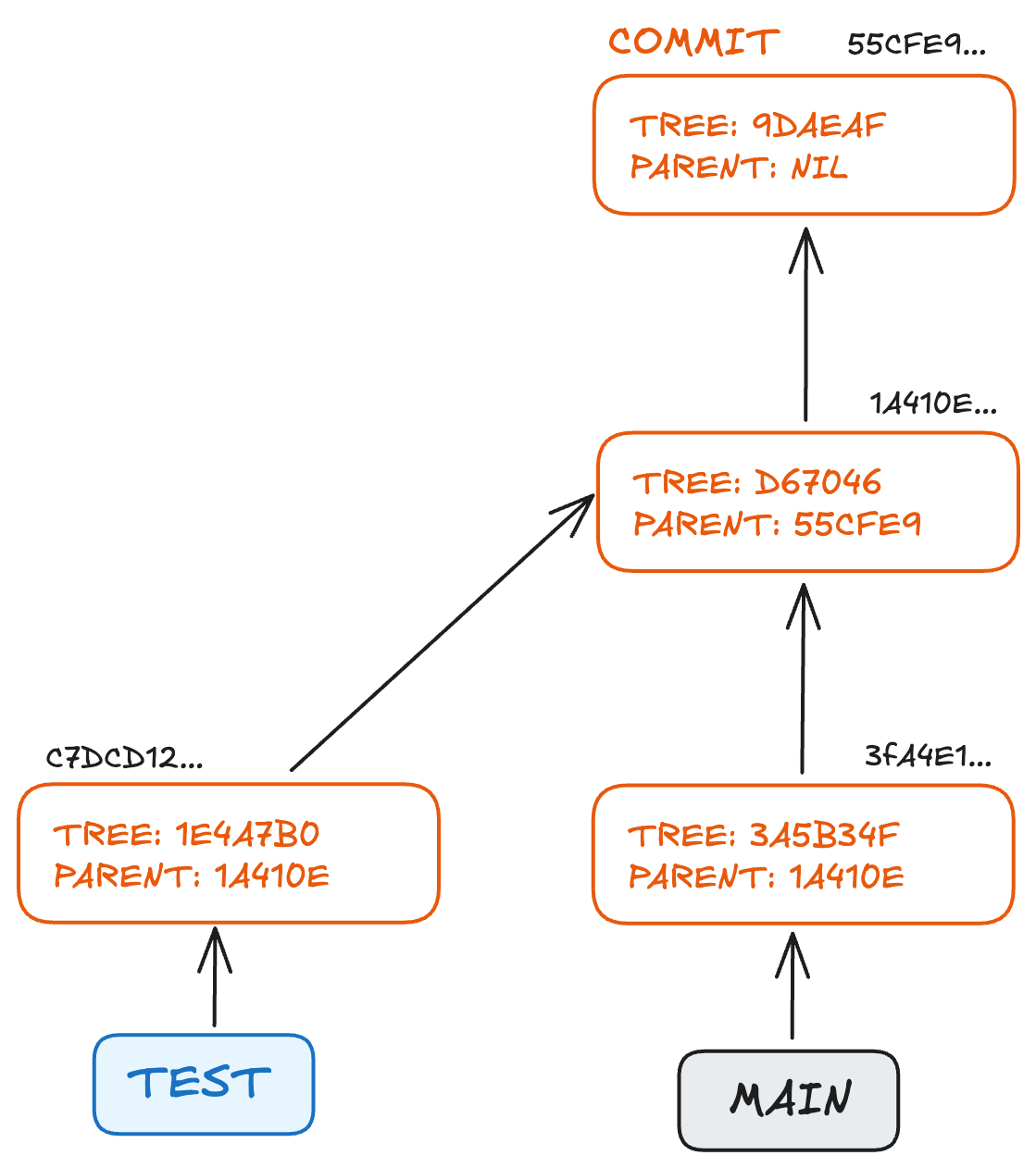
Commit names are difficult for humans to remember, so this is where branches come in.
A branch is just a named reference to a commit, like a label. The default branch is called main or master, and it points to the most recent commit.
If a new branch is created, it will also point to the most recent commit. But if a new commit is made on the new branch, that commit will not exist on main.
This is useful for working on a feature without affecting the main branch.
Based on how Git keeps track of a project, it is possible to do things that will make objects unreachable.
Here are three different ways this could happen:
1. Deleting a branch: Deleting doesn't immediately remove it but removes the reference to it.
Reference is like a signpost to the branch. So the objects in the deleted branch still exist.
2. Force pushing. This replaces a remote branch's commit history with a local branch's history.
A remote branch could be a branch on GitHub, for example. This means the old commits lose their reference.
3. Removing sensitive data. Sensitive data usually exists in many commits. Removing the data from all those commits creates lots of new hashes. This makes those original commits unreachable.
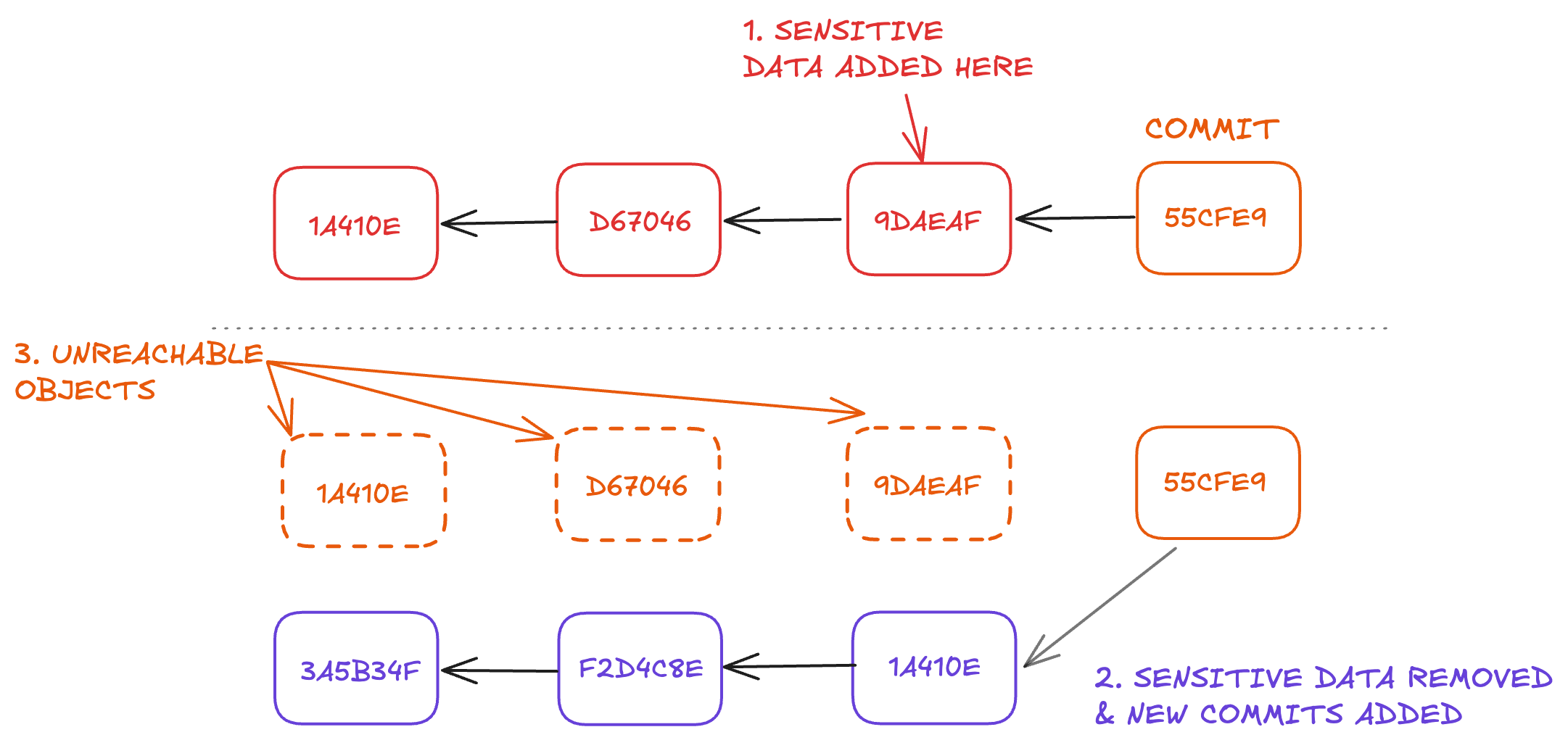
There are many other ways to make unreachable objects, but these are the most common.
Usually, unreachable objects aren't a big deal. They typically get removed with Git's garbage collection.
Sidenote: Git's Garbage Collection
Garbage collection exists to remove unreachable objects.
It can be triggered manually using the git gc command. But it also happens automatically during operations like git commit, git rebase, and git merge.
Git only removes an object if it's old enough to be considered safe for deletion. This is typically 2 weeks. In case a developer accidentally deletes objects and they need to be retrieved.
Objects that are too recent to be removed are kept in Git's objects folder. These are known as loose objects.
Garbage collection also compresses loose, reachable objects into packfiles. These have a .pack extension.
Like most files, packfiles have a single modification time (mtime). This means the mtime of individual objects in a packfile would not be known until it’s uncompressed.
Unreachable loose objects are not added to packfiles. They are left loose to expose their modification time.
But garbage collection isn't great with large projects. This is because large projects can create a lot of loose, unreachable objects, which take up a lot of storage space.
To solve this, the team at GitHub introduced something called Cruft Packs.
Cruft Packs to the Rescue
Cruft packs, as you might have guessed, are a way to compress loose, unreachable objects.
The name "cruft" comes from software development. It refers to outdated and unnecessary data that accumulates over time.
What makes cruft packs different from packfiles is how they handle modification times.
Instead of having a single modification time, cruft packs have a separate .mtimes file.
This file contains the last modification time of all the objects in the pack. This means Git will be able to remove just the objects over 2 weeks old.
As well as the .pack file and the .mtimes file, a cruft pack also contains an index file with an `.idx` extension.
This includes the ID of the object as well as its exact location in the packfile, known as the offset.
Each object, index, and mtime entry matches the order in which the object was added.
So the third object in the pack file will match the third entry in the idx file and the third entry in the mtimes file.
The offset helps Git quickly locate an object without needing to count all the other objects.

Cruft packs were introduced in Git version 2.37.0 and can be generated by adding the --cruft flag to git gc, so git gc --cruft.
With this new Git feature implemented, GitHub enabled it for all repositories.
By applying a cruft pack to the main GitHub repo, they were able to reduce its size from 57GB to 27GB, a reduction of 52%.
And in an extreme example, they were able to reduce a 186GB repo to 2GB. That's a 92% reduction!
Wrapping things up
As someone who uses GitHub regularly I'm super impressed by this.
I often hear about their AI developments and UI improvements. But things like this tend to go under the radar, so it's nice to be able to give it some exposure.
Check out the original article if you want a more detailed explanation of how cruft packs work.
Otherwise, be sure to subscribe so you can get the next Hacking Scale article as soon as it's published.
PS: Enjoyed this newsletter? Please forward it to a pal or follow us on socials (LinkedIn, Twitter, YouTube, Instagram). It only takes 10 seconds. Making this one took 20 hours.